前回の記事では、Mayaの「Matrix(オフセット親行列)」について解説しました。
その4x4行列の中に現れる謎の小数点の正体は「 $\cos(45^\circ)$ などの数値だった」という話をしました。
「サイン・コサイン…」
ド文系の私からすると、思い出すだけで頭がクラクラしてきます(笑)。
最初は、「Matrix VS Constraint」というテーマで、1万個のポリゴンキューブを1つのロケーターでグルグル回すだけの、単純な負荷テスト用のシーンを作りました。
しかし、その動きを見ているうちに、ふとこんな思いが湧いてきました。
「せっかくの圧倒的な処理パワー(9950X3D)なので、ただ四角い箱が回っているだけでは面白くない。もっと視覚的、数学的に美しいアニメーションで表現できないだろうか?」
そこで、壁打ち相手であるAI(Gemini)に相談してみました。
「Matrixの軽さを活かして、数学的に美しい無限ループアニメーションを作りたい!」と。
私は3Dアニメーターなので、いろいろなアニメーションを作ってきましたが、「数学的に美しいアニメーション」というものを作ったことがありません(というよりもド文系なので作れませんでした)。
そうして完成したのが、4つのオリジナル・ベンチマークシーン(.maファイル)です。
単なる重さ比べのパフォーマンステストではなく、「Constraintの重さ」と「Matrixの圧倒的な軽さ」を証明しつつ、数学が描き出す美しいテクニカルアートに挑戦してみました。
無料でダウンロードできるようにしましたので、ぜひご自身のPC環境でテストしてみてください!
(※本記事は、「ド文系のためのMatrix入門」というコンセプトを踏襲しつつ、リガー向けの少しマニアックな「評価マネージャ(Evaluation Manager)」の深層解説も含んでいます!)


第1章:基礎戦闘力の証明「10K Swarm(大群)」と、評価マネージャの真実
まずは、純粋なノード処理速度の違いを測るためのベースラインとなる検証です。
1万個のボックス(ポリゴンキューブ)を生成し、それをたった1つのロケーターで回転させるという、非常にシンプルなシーンを用意しました。数式は使わず、単純な親子の動きだけの純粋な力比べです。
今回の検証に使用した環境は以下の通りです。
- GPU:NVIDIA GeForce RTX 5090
- CPU:Ryzen 9 9950X3D(16コア / 32スレッド)
- メモリ:96GB
- OS:Windows 11 pro
- Software:Maya2026
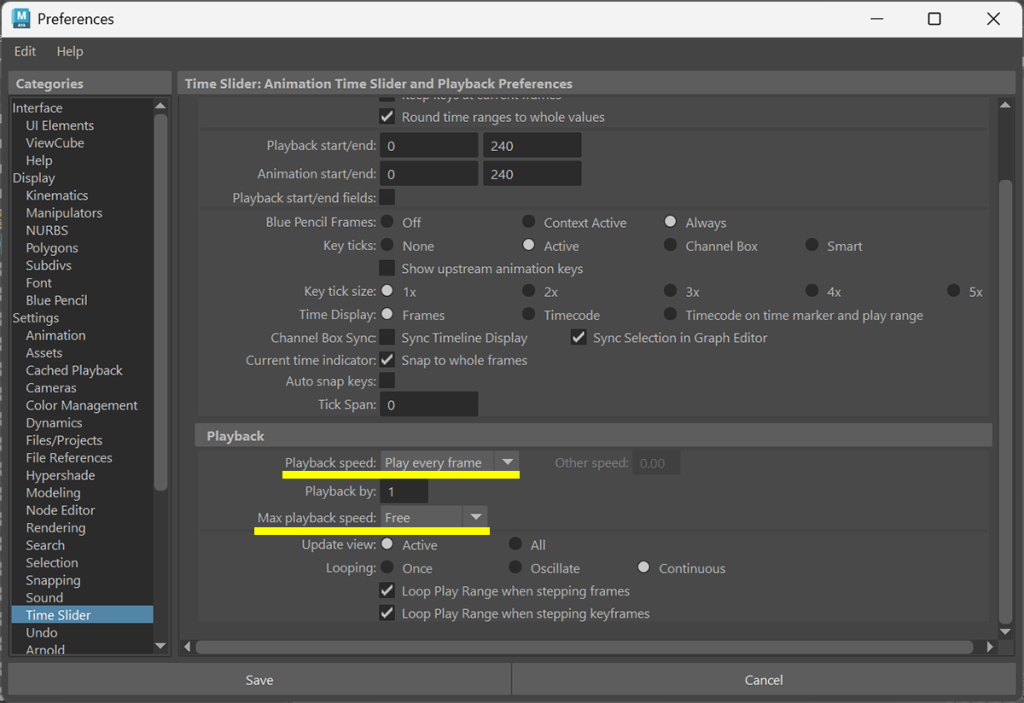
1つのコントローラー(ロケーター)で1万個のボックスを「offset Parent Matrixで繋いで動かしたもの」と「Parent Constraint(オフセットつき)で繋いで動かしたもの」では、パフォーマンスにどれほどの違いがあるのかを実験してみました。
24fpsで240フレーム(10秒)でrotate.Z軸で1回転するアニメーションです。
設定はPlayback speedは「Play every frame」。
Max Playback speedは「Free」です。
この状態で再生したときのパフォーマンスを比べる実験を行いました。
| 評価モード | Parent Constraint | offset Parent Matrix |
|---|---|---|
| DG(Dependency Graph) | 2.8~2.9fps | 6.2~6.4fps |
| Serial | 3.1fps | 6.6~6.7fps |
| Parallel | 35~36fps | 65~66fps |
現行最強クラスのCPUをもってしても、Constraintで1万個のノードを繋ぐと「35fps」にとどまります。
対してMatrix版は、なんと約2倍の「65fps」という驚異的な数値を叩き出しました!
1万個のオブジェクトを動かしながら60fpsの壁を余裕で越えてくるRyzen 9 9950X3Dの並列処理能力(Parallel)にも驚きですが、ノードの計算渋滞を起こさない「Matrix(オフセット親行列)」の処理効率がいかに優れているかがよく分かります。
【コラム】RTX 5090は手伝ってくれない?「GPU Override」の誤解
「設定(Preferences > Settings > Animation)の『GPU Override(GPUのオーバーライド)』にチェックを入れて、RTX 5090に計算を手伝わせればもっと速くなるんじゃないの?」
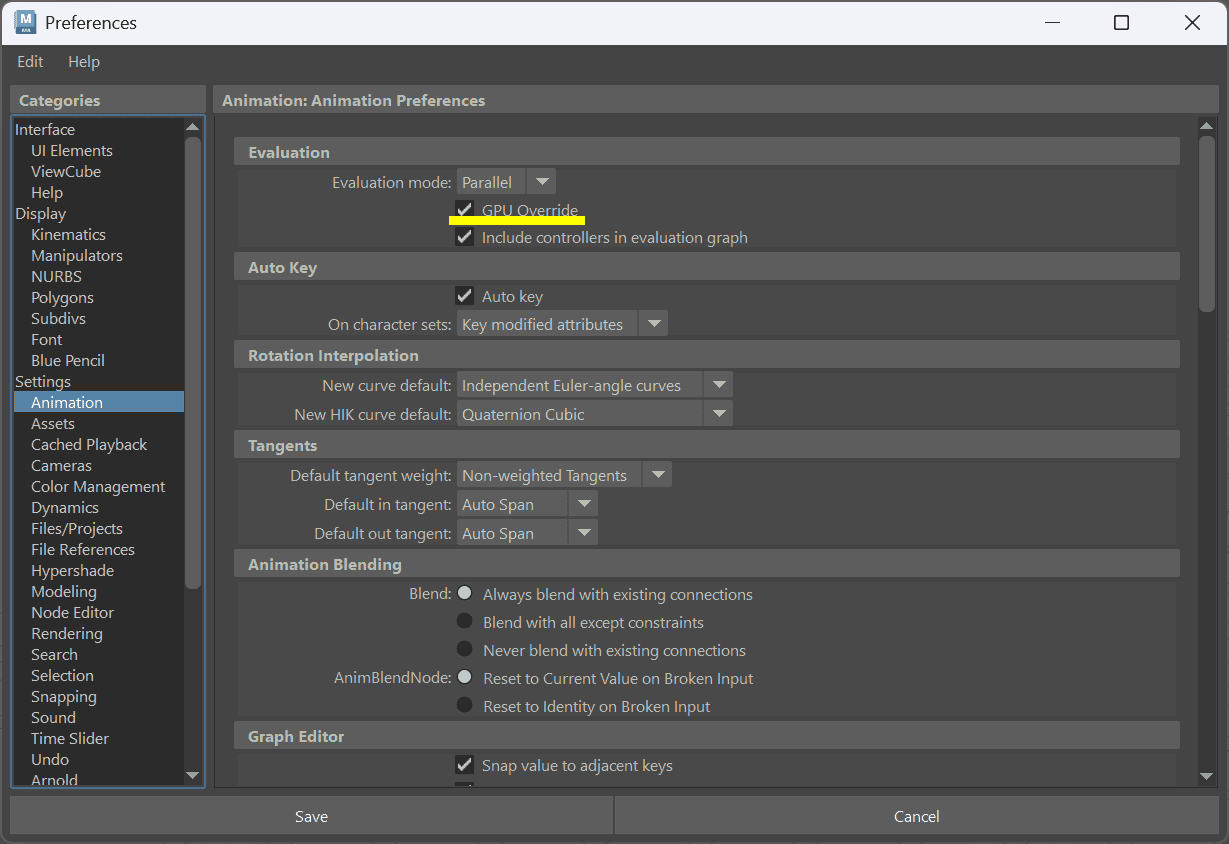
実はここが、Mayaのパフォーマンスを語る上で最も誤解されやすいポイントです。
結論から言うと、この検証においてRTX 5090は計算を一切手伝ってくれません。
Ryzen(CPU)が100%の仕事を行っています。
なぜなら、MayaがGPUに丸投げできるのは「スキンウェイトやブレンドシェイプなど、1つのオブジェクトの頂点がぐねぐね変形する計算(デフォメーション)」だけという厳格なルールがあるからです。
今回のような「変形しない箱の移動・回転・ノード接続」は、すべてCPUしか処理できません。
だからこそ、このベンチマークはグラボの性能に誤魔化されない「純度100%のCPU演算テスト」になります。
第2章:リグ初心者向け!Mayaの3つの計算モードの違い
アニメーション設定(Preferences > Settings > Animation)にある「評価モード(Evaluation Mode)」。
- DG(Dependency Graph)
- Serial
- Parallel
わかりやすいように、Mayaがノードを計算する3つの評価モード「DG」「Serial」「Parallel」の違いを、「1万枚の書類にハンコを押す事務作業」に例えて整理しておきましょう。
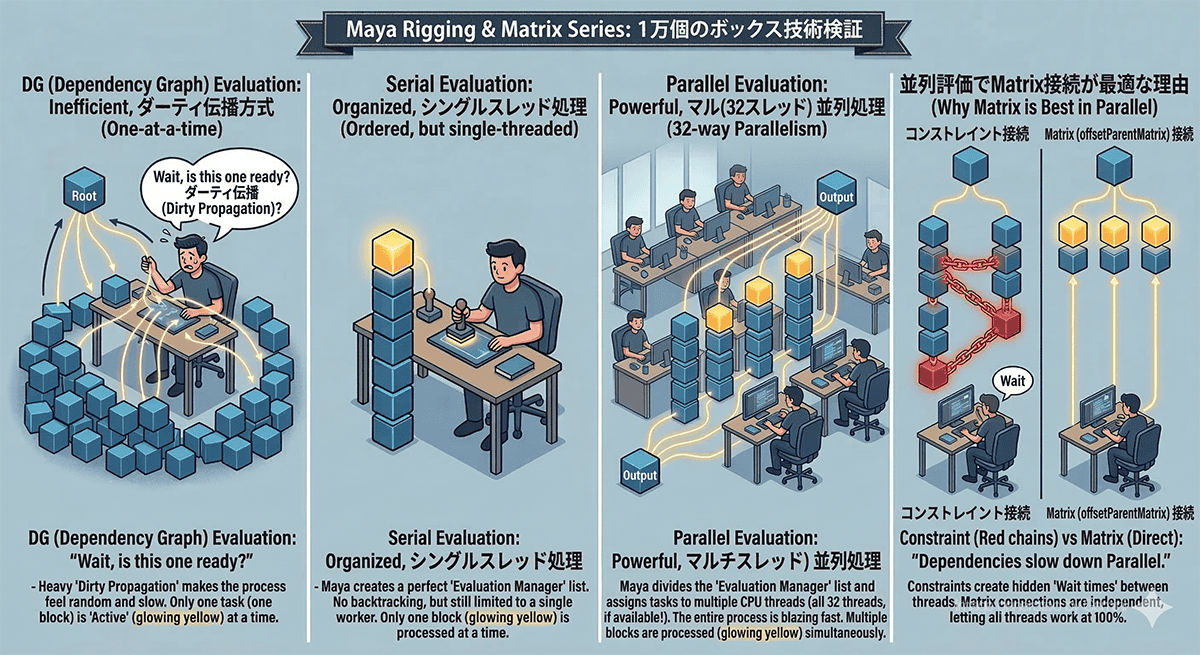
DG(Dependency Graph)モード:昔ながらの「行き当たりばったりハンコリレー」
大昔のMayaから使われている、最も古い計算方法です。
例えるなら、「全体図を持たずに、その場しのぎでハンコを回す古いオフィス」です。
作業員は1人だけ。
書類にハンコを押す前に「この書類、前任者の計算終わってる?」といちいち前の部署(親ノード)へ走って確認しに行きます。
ハンコを押す時間より、確認して回る時間の方が長い古いシステムです。
Parallel(並列)モード:マニュアル完備!「複数人で一斉ハンコ押し」
現在のMayaの標準であり、最強のモードです。
ファイルを開いた瞬間に、誰がどの順番でハンコを押せばいいのか、全手順が書かれた「完璧なハンコ押しマニュアル(評価グラフ)」をあらかじめ作成します。
そのマニュアルを見たMayaは指示を出します。
「よし、この1万枚の書類は順番待ちしなくていいやつだな!お前ら、一斉にハンコ押せ!」 この指示を受け、Ryzen 9 9950X3Dのような強力なマルチコアCPU(たくさんの優秀な社員)が、全員で一斉に分担してハンコを押しまくります。
だからこそ「65fps」という爆速が叩き出せるのです。
Serial(直列)モード:マニュアルはあるけど「1人で順番にハンコを押す」
ここが勘違いされやすいポイントです。
Serialは、Parallelと全く同じ「完璧なハンコ押しマニュアル」を最初に作ります。
しかし、それを複数の社員に配らず、あえて1人の社員(CPUの1つのコア)だけで、マニュアル通りに順番にハンコを押していくモードなのです。
【深堀り解説】「Serial(直列)」モードって必要?
マニュアルを作ったのに、なぜ「わざわざ1人でハンコを押す」のでしょうか。
実は、このSerialモードはリガーのための「バグ調査(デバッグ)専用モード」として存在しているのです。
Serial(直列)モードの使い方
自作したリグを動かしたら、ビューポートで破綻しちゃった…なんで!?
そんな時、原因は大きくわけて2つあります。
- 原因A: そもそも作った「ハンコ押しマニュアル(ノードの組み方)」が間違っている。
- 原因B: マニュアルは合っているが、複数人で同時にハンコを押させようとしたせいで、書類の受け渡しタイミングがズレてパニックになった(スレッド間の競合)。
ここで評価モードを「Serial」に切り替えます。
もし、Serial(1人での順番作業)にして正しく動いたならば、「原因B(複数人でのタイミングズレ)」が犯人。
Serialでも破綻したままならば、「原因A(リグの組み方が根本的に間違っている)」と原因を切り分けることができるのです。
単に「Serialは古い」というわけではなく、プロの現場で原因究明をするための重要な役割を持っているわけです。
【知っ得コラム】アニメーターは知らない?「コントローラータグ」と評価グラフの深い関係
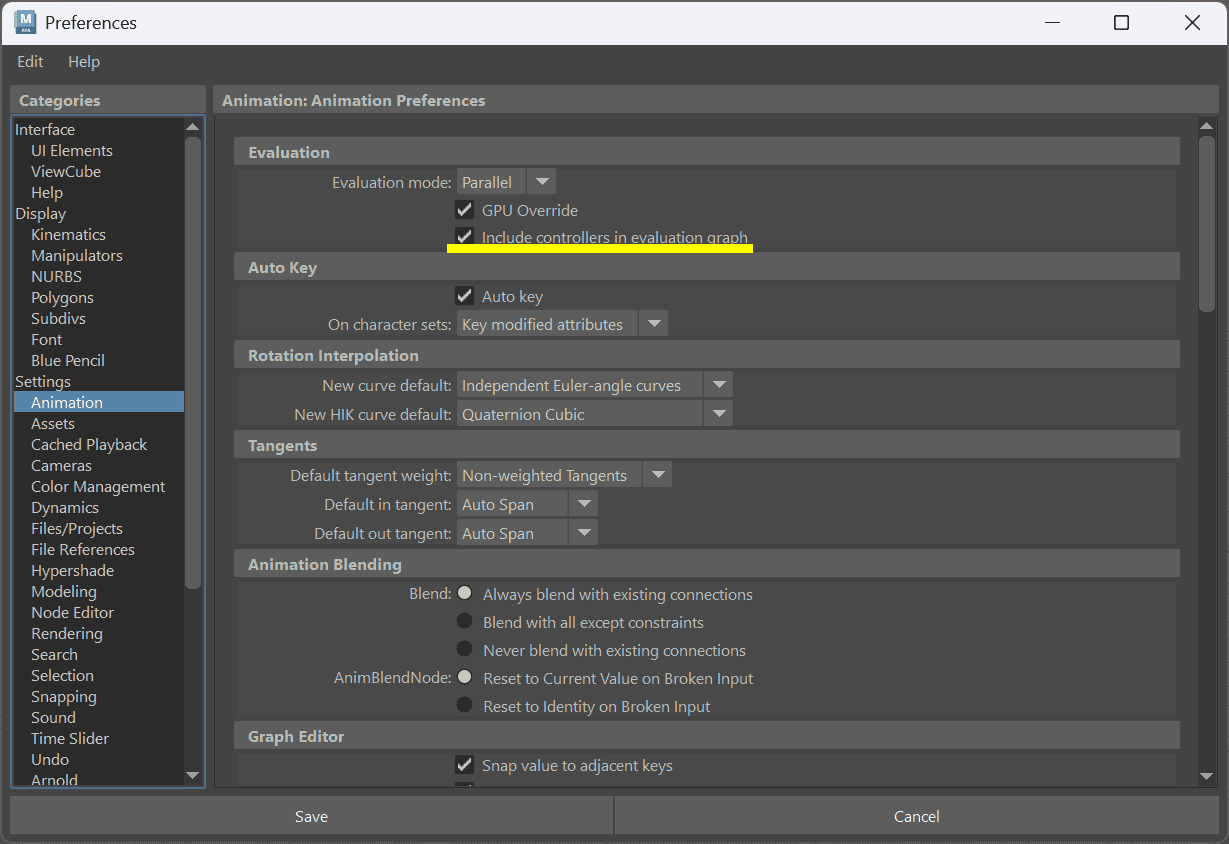
アニメーション設定画面で、評価モードの下にもう一つ気になるチェックボックスがありますよね(GPU Overrideについてはすでに説明しました)。
「Include controllers in evaluation graph(評価グラフにコントローラーを含める)」。
英語で書かれていると難しそうですが、ハンコの例え話が分かった皆さんならもう理解できます。
これは、Mayaが 「完璧なハンコ押しマニュアル(評価グラフ)」を作る際のオプション です。
実はこのチェックボックスの本当の意味を理解するには、少しだけリガーの裏話を知る必要があります。
私たちがキャラクターを動かす時、普段当たり前のように触っているNURBSカーブのコントローラー。
Mayaのシステムから見れば、最初はただの「線(geometry)」でしかありません。
しかし、リガーが上部メニュー「Rigging」から 「Control > Tag As Controller」 という処理を行うことで、そのカーブに 「こいつはアニメーターが直接触るVIPだぞ!」という目印(タグ) が付きます。

「長年アニメーションをつけてきましたが、裏でそんなタグ付け作業が行われていたなんて、恥ずかしながら全然知りませんでした!」
このチェックボックスをONにしておくと、Mayaがマニュアルを作る時に、まず最初に「VIPの目印(タグ)」が付いているノードを探し出します。
そして、 「よし、アニメーターが直接動かすのはコイツらだな!ここを一番最初の出発点(起点)として、無駄のない完璧なハンコリレーの順番を組もう!」 と、より賢く、より爆速で動く計算スケジュールを組んでくれるようになります。
ちなみに、最近主流になっている自動リグツール(『mGear』や『Advanced Skeleton』など)でリグを組むと、実は裏で自動的にこのタグ付けを行ってくれています。
アニメーターがビューポートでコントローラーを触った時に、「Parallel」の恩恵を120%引き出してヌルヌル動かすための、リガーとMayaの美しい連携プレイだったのです!
ご自身でリグを組むリガーの方は、忘れずにタグ付けをして、この恩恵をしっかり受け取りましょう。

第3章:プロファイラ(Profiler)が暴く残酷な真実
先ほどの表で、Matrix接続が「65fps」という圧倒的な数値を叩き出したことは分かりました。
では、なぜ同じようにノードを繋いでいるだけなのに、ここまで露骨な差が出るのでしょうか?
その答えは、Mayaに標準搭載されている「プロファイラ(Profiler)」という機能を使うと、残酷なほどハッキリと視覚化されます。
プロファイラとは、PCの頭脳であるCPU(今回の場合はRyzen 9 9950X3Dの32スレッド)が、「どのタイミングで・誰が・どんな計算をしているか」をミリ秒単位でレントゲン写真のように覗き見ることができる機能です。
それでは、1万個のボックスを動かした時のCPUの「働きっぷり」を覗いてみましょう。
悲劇のDG評価:確認作業でフリーズする工場
まずは、一番遅かった(約6fps)古いDG評価モードで動かした結果です。
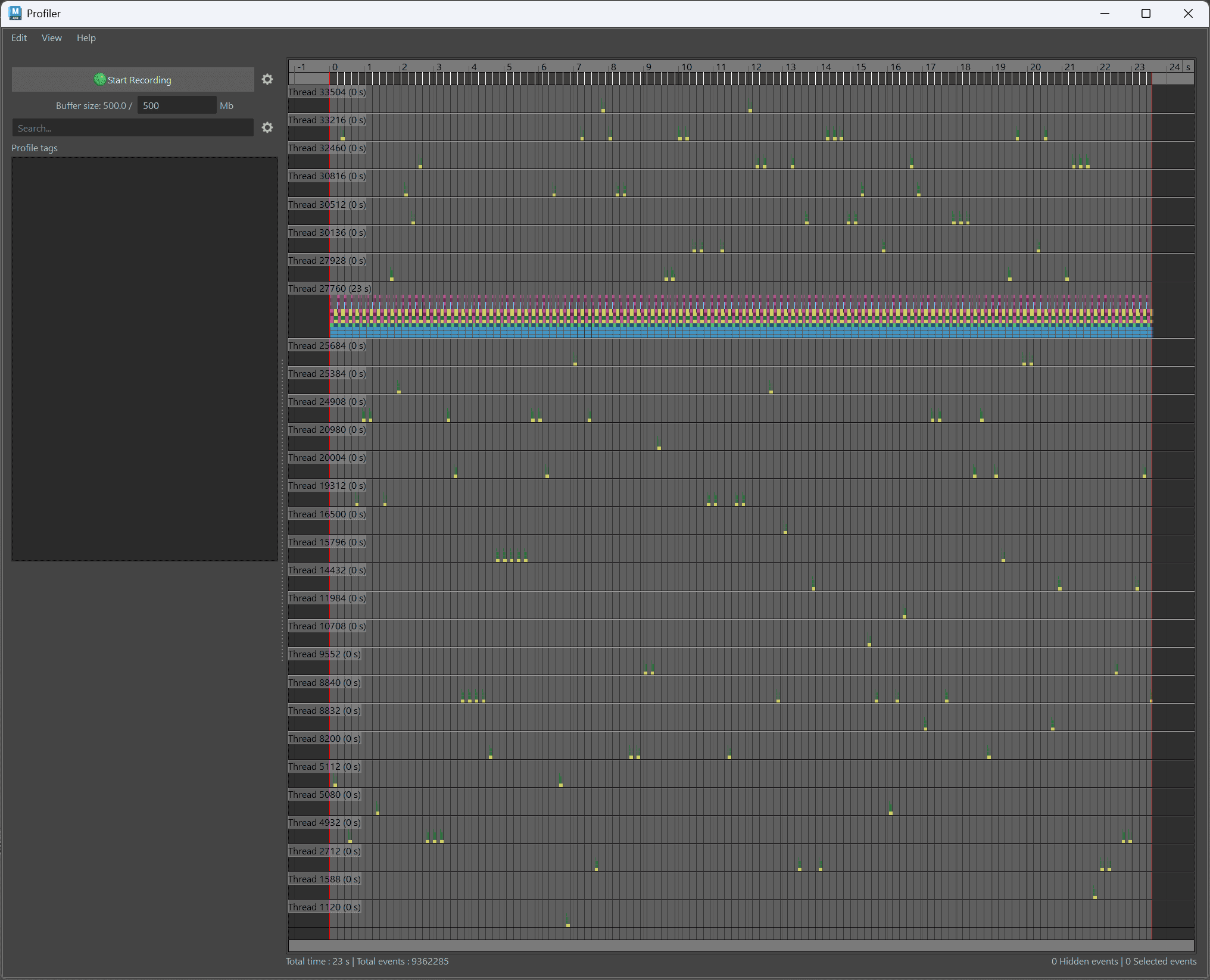
中央のメインスレッド(現場監督)だけがギッチギチに働かされて過労死寸前になっているのに対し、上下にいる残りの31人の作業員(優秀なCPUコアたち)は、たまにポツンと動くくらいで完全に暇を持て余してサボっています。
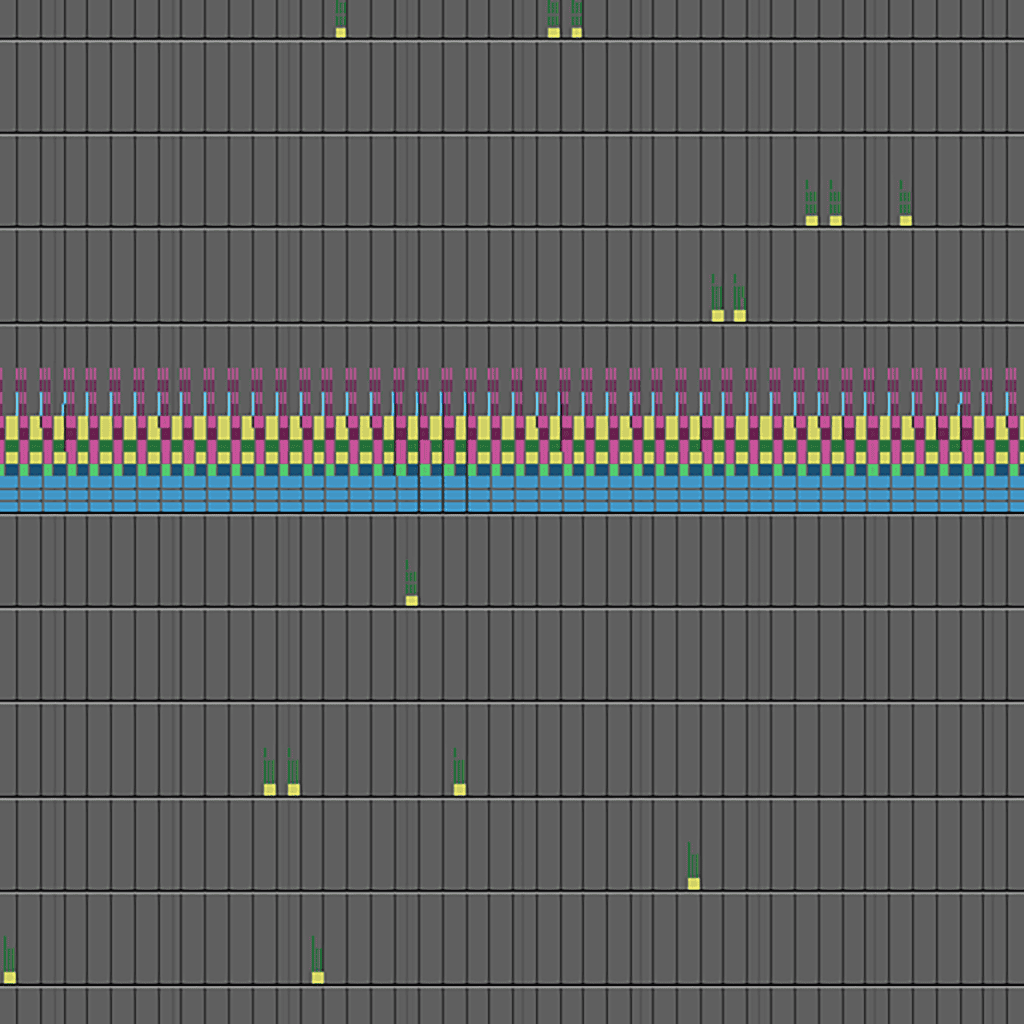
さらに、中央の行に横に長く伸びている「ピンク色の巨大なブロック」に注目してください。これが「Dirty Propagation(ダーティ伝播)」です。
【深淵の解説】プロファイラを埋め尽くす「ピンクのブロック」の正体
かつての名著『Complete Maya Programming』(現在は絶版)などでも語られていたMayaの内部構造に、「ダーティビット(Dirty bit)」という仕組みがあります。
\お手頃な価格の中古品があれば、読んでみても良いかもしれません/

Mayaのノードは、常に自分が持っているデータが「最新(Clean)」か「古いから再計算が必要(Dirty)」かを、見えないスイッチ(ビット)で管理しています。
DGモードは、このスイッチをバケツリレーのように一つ一つ手作業で切り替えていく古いシステムです。
これを先ほどの「ハンコ工場」で例えると、このピンク色のブロックの恐ろしさがよく分かります。
- ロケーター(社長)が「すまん、やっぱり元の企画書ちょっと直すわ!」と中身を動かします。
- すると、伝令係の社員(Maya)が、1万人の作業員のデスクを一つ一つ走り回って、「企画書が変わりました!あなたの手元にある書類には『要・再計算(ダーティビット)』の赤い付箋を貼ってください!」と叫びながら付箋を配り歩きます。
- この赤い付箋を1万人に貼り終わるまで、誰もハンコを押す(実際の計算)作業に入れません。
つまり、このピンク色のブロックの正体は、実際のハンコ作業ではなく「お前もDirty(要・再計算)な!お前もDirtyな!」と1万人に赤い付箋を貼って回っているだけの無駄な確認時間なのです。
この伝言ゲームだけで時間を消費し、その間、Ryzen 9 9950X3Dの超優秀なコアたちは完全に立ち往生しています。これがDGモード最大の悲劇です。
Parent Constraintの限界:見えない「小さな順番待ち」
次に、評価モードを最新の「Parallel」にし、1万個のParent Constraintを動かした結果です。
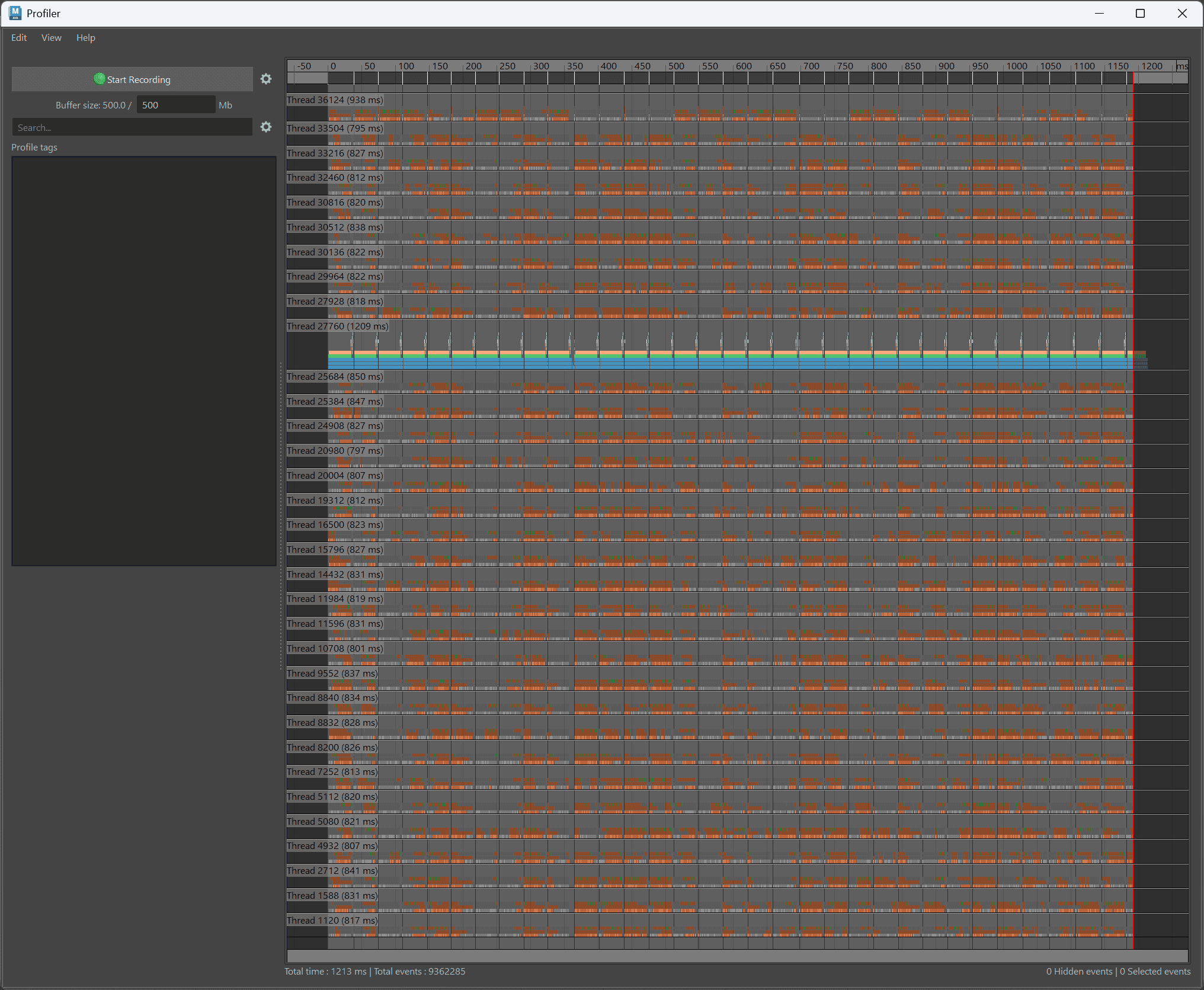
パッと見ると、「あれ?全スレッド(32人の作業員)が綺麗に働いているじゃないか」と思うかもしれません。
しかし、次のMatrixの画像と比べると、1フレーム分(縦の列の塊)の横幅が太く、計算そのものに時間がかかっていることがわかります。
さらに画像を拡大して、オレンジ色のブロックをよく見てください。

ブロックとブロックの間に、チラホラと「黒い隙間(何もしていないアイドル時間)」が混ざっているのが分かるでしょうか?
実はこれ、コンストレイント特有の「依存関係(ルールの縛り)」によるものです。
全員で一斉に作業をしてはいるものの、計算が複雑なため内部では「俺の書類、Aさんの承認が終わるまで数ミリ秒待たなきゃ…」という『目に見えないほどの小さな順番待ち(黒い隙間)』が大量に発生しているのです。
この微小なロスの積み重ねが足を引っ張り、最新(最強)CPUをもってしても「35~36fps」にとどまってしまう原因となっています。
でも、次の「offsetParentMatrix」と区別がつきにくいのは、いかに9950X3Dが優秀かを物語っているとも言えます。
Matrix接続の完全勝利:隙間なくギッシリ詰まった「最速の壁」
最後に、同じParallel評価で、1万個のMatrix(offsetParentMatrix)接続を動かした結果です。
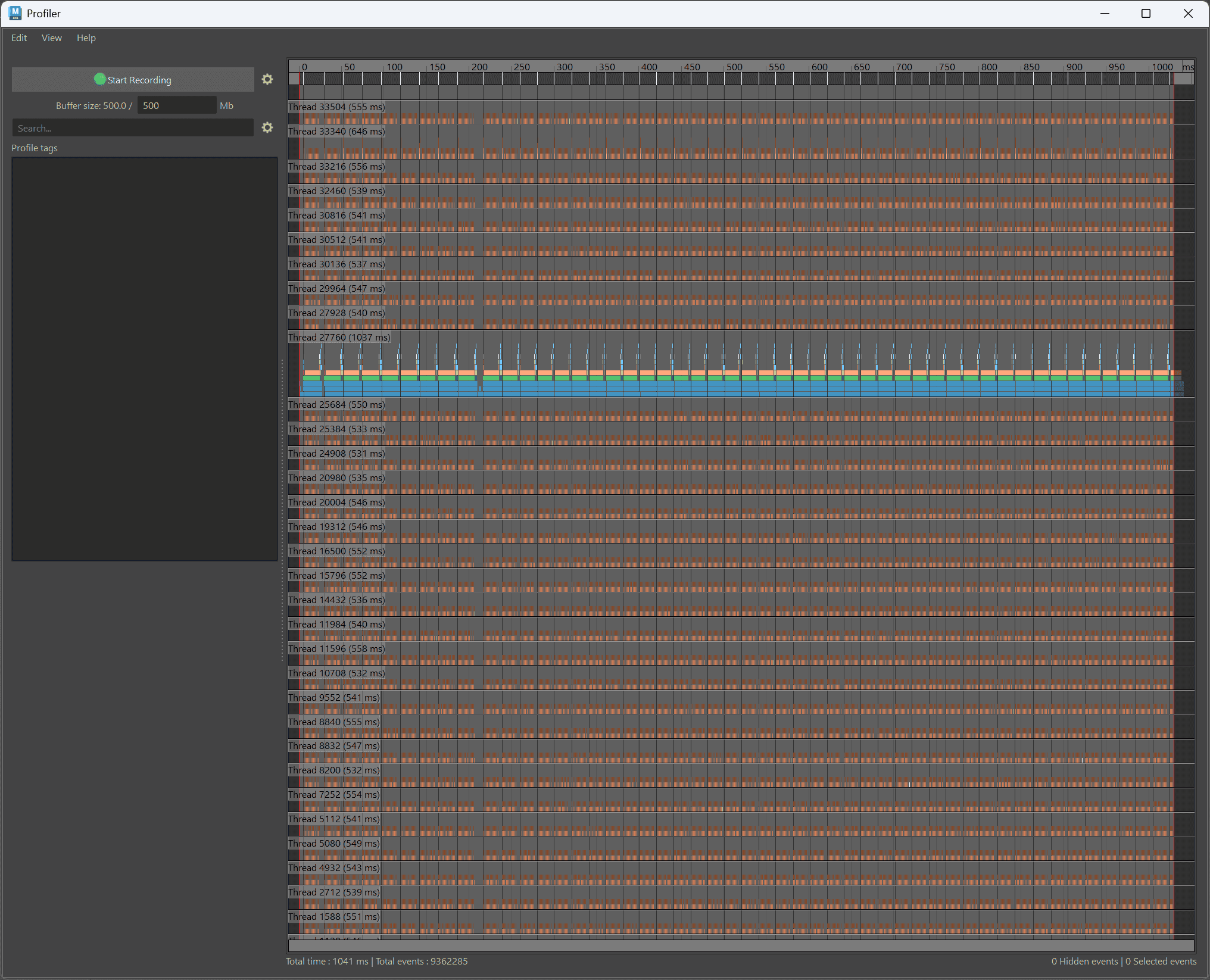
先ほどのコンストレイントの画像と見比べてみてください。
1フレーム分の横幅が圧倒的に細く(速く)なっていますよね(わかりづらいけど(笑))。

そして何より、オレンジ色のブロックの間に黒い隙間がほとんどなく、ギッシリと詰まった美しいレンガの壁になっています。
Matrix接続は、親の行列データをもらうだけで自分自身の計算が完結するため、「他人の進行状況(承認)を一切気にしなくて良い」のです。
だからこそ、32個の全スレッドがノンストップで限界までスピードを出し切り、わずか数十ミリ秒という一瞬で1万個の計算を終わらせる(65~66fpsを叩き出す)ことができるのです!
「Ryzen 9 9950X3Dの32スレッドが、誰一人サボらずに一斉にハンコを押しまくっているこの美しい波形…。これを見た時、Matrixのあまりの無駄のなさに感動!」
なぜMatrix接続はマルチコアCPUの恩恵を受けやすいのか?
なぜコンストレイントだと渋滞が起き、Matrix接続だとスレッドがフル稼働するのでしょうか。
理由は「計算の独立性」にあります。
コンストレイントは、「Aが終わらないとBに進めない」という複雑な依存関係(ルールの縛り)を大量に生み出します。そのため、せっかく32人の作業員がいても「俺の書類、Aさんの承認待ちだわ…」と手が止まる人が続出してしまうのです。
一方、Matrix接続は中間ノードがなく、親の行列データをもらうだけで計算が完結します。1万個のボックスすべてが「他人の進行状況を一切気にしなくて良い独立した書類」になるため、全作業員がノンストップで最高速を出せるというわけです。
第4章:ド文系がAIと創った芸術!3つの「変態的」ベンチマーク
ここまで、第1章から第3章にかけて「Level 1:1万個の単純回転(10K Swarm)」を使った基礎テストで、Matrixの圧倒的な処理スピードと、マルチコアCPUの凄さがお分かりいただけたかと思います。
ここまでで、Matrixの圧倒的な処理スピードと、マルチコアCPUの凄さがお分かりいただけたかと思います。
しかし、ただ1万個の箱が回っているだけでは面白くありません。
「この有り余るパワーと、Matrixの身軽さを活かして、数学的に美しいアニメーションを作ってみたい!」
そんなド文系の私の無茶振りに、AI(Gemini)が数式を駆使して応えてくれました。
ここからは、単純な回転(Level 1)から劇的な進化を遂げた、CPUの限界に挑む「3つのオリジナル・数学ベンチマーク(Level 2〜4)」の世界をご紹介します!
または、GUMROADよりダウンロードしてください。
Level 2:マウンテンウェーブ(サイン波と減衰の芸術)
前回の記事で少し触れた「サイン・コサイン」をフル活用したベンチマークです。
平面に敷き詰めた1万個のキューブに対して、三角関数の「サイン波(Sine wave)」を使って高さを制御しています。
ただのサイン波を流し込むだけではトタン屋根のような「平行な波」にしかならないため、各キューブのX座標とZ座標から「中心からの距離」を割り出し、「中心から離れるほど波が小さくなる(減衰する)」という計算を足すことで、中央が隆起した「山(マウンテン)」のような波紋を作り出しました。
各キューブのX座標とZ座標から「中心からの距離」を割り出し、それを波の数式に組み込んでいます。さらに「中心から離れるほど波が小さくなる(減衰する)」という計算を足すことで、中央が隆起した「山(マウンテン)」のような波紋を作り出しました。
そしてここからが、このベンチマークの真骨頂です。
AIと数式でこの美しい動きを作った後、実はこの1万個のキューブすべてのアニメーションをベイク(キーフレーム化)しています。
つまり、1万個のノードそれぞれに、毎フレームごとの膨大なアニメーションカーブのデータが流し込まれているという、超絶ヘビーな状態です。
これほど過酷な負荷テストであっても、Matrixの並列処理(Parallel)の恩恵により、驚くほど滑らかに再生されます。
ド文系の私からすると、数式だけでこの有機的で美しい動きが作れることに、ただただ感動です。
Level 3:サイバー・トルネード(円錐螺旋の乱気流)
さらに数学のレベルを一段階上げます。
平面の波打ちから、今度は高さを表すY軸も絡めた「円錐螺旋(えんすいらせん)」という数式を使いました。
下から上へ向かって広がりながら回転する竜巻の動きに、サイン波の「揺らぎ」を足すことで、それぞれのキューブが風に煽られているような乱気流を表現しています。
そしてこのLevel 3でも、AIに組んでもらった数式の動きを、1万個のキューブすべてにアニメーションとしてベイク(キーフレーム化)しています。
1万個のノードが空間をダイナミックに飛び交い、しかもすべてのノードが毎フレームびっしりと打たれたカーブデータ(膨大な計算量)を読み込んでいるという、極めてアグレッシブな負荷テストです。
しかし、これだけ激重なキーフレームの嵐の中にあっても、Matrix接続と最新CPUの並列処理パワーは一切怯むことなく、美しい乱気流を滑らかに描き切ります。
Level 4:無限ギア(フィボナッチ・スフィアの極致)
そして最後のベンチマークがこちら。
「フィボナッチ数列」と「黄金比」を使った、究極の高密度テストです。
3DCGで球体(sphere)を作ると、どうしても一番上と下の「極」の部分に頂点が密集してしまいます。
しかし、ひまわりの種の並び方など、自然界に存在する「黄金比」の数式を使って配置すると、1万個のキューブが一切重なることなく、完璧に均等な密度で美しい球体を形作るのです。
そして、このベンチマークのフィナーレを飾る最大の負荷として、1万個のキューブがそれぞれ自転しながら全体として回り続けるという複雑怪奇な動きも、すべてアニメーションとしてベイク(全フレームキー化)してあります。
1万個のキューブがそれぞれ自転しながら、全体としても絶対に破綻せずに回り続ける…。
Matrix接続と最新(最強)CPUのパワー、そして数学のロマンが融合した、このベンチマークのフィナーレにふさわしい激重(でも美しい)シーンです!
「あまりの高速回転に目が回りそうになりますが、フィボナッチ配列の完璧な秩序が生み出す『美しいうねり』に注目してみてください」
または、GUMROADよりダウンロードしてください。
コラム:Maya「Parallel評価」の進化の歴史とトラウマ
「Parallelモードって、リグがバグったり壊れたりするから信用できないんだよね…」
もしあなたが10年(あるいは5年)以上Mayaを使っているベテランなら、そう思っていませんか?
実は、私も最近までそう思っていました…。
Parallel評価が導入されたMaya 2016当時、システムがまだ成熟しておらず、古い組み方のリグが盛大に破綻するケースが多発しました。それがトラウマになっているリガーは少なくありません。
しかし、状況はMaya 2019の「Cached Playback」の導入を機に激変しました。
キャッシュ機能を安定稼働させるため、Autodeskは評価マネージャを根本から改修し、現在のParallel評価は当時とは別次元の安定性を誇っています。
さらにMaya 2020での「 offsetParentMatrix」 の標準機能化により、リグ自体が「Parallelで壊れにくい(=並列化しやすい)構造」へと進化しました。
過去のトラウマで無意識に「DG」や「Serial」に逃げてしまっているベテランこそ、今のMayaのParallel評価とMatrix接続のパワーを信じてみてください。
過去のトラウマやDG時代の名残りから、「リグは重くて当たり前」「下手に新しいノードを使うとバグる」と思いこんでいないでしょうか?
昔ながらのコンストレイント主体の組み方に無意識に固執してしまっているベテランこそ、今のMaya 2026のParallel評価とMatrix接続のパワーをぜひ信じてみてください。
ちょっとマニアックな補足:なぜMayaアニメーターに「多コアCPU」が必須なのか?
初心者の方は「リグが軽いと速い」くらいの認識で全く問題ありません。
ただ、もしあなたがご自身でリグを組んだり、重いシーンを扱う中級者以上であれば、今回のプロファイラ画像が示す意味に気がついたはずです。
Matrix接続でどれだけリグを最適化(並列化)しても、作業マシンのCPUコア数・スレッド数が少ないと、物理的な限界がすぐに来てしまいます。
私の検証環境(Ryzen 9 9950X3D)で圧倒的なパフォーマンスが出たように、3DCGアニメーターにとって「自分の作業に対して、どこにお金をかければ一番快適になるのか」を知っておくことは非常に重要です。
最近はAIの台頭などでGPUばかりにフォーカスが当たっている状況なので、この記事は、あえて、CPUにフォーカスしてみました。
今回はCPUのパワーの検証を行いましたが、もちろん、GPUの能力も必要なのは言うまでもありません。
パソコンの買い替えやスペックアップを検討している方は、以下の記事も参考にしてみてください。


まとめ:Matrixが切り拓く、次世代のMaya表現と限界突破
今回の検証で、Matrix接続がこれまでのコンストレイントに比べてリグを驚くほど軽量化できることが証明されました。
しかし、Matrixの本当の凄さは、単なる「軽さ」だけではありません。
階層構造(ヒエラルキー)に縛られない自由な親子関係を構築できる「モジュラーリギング」の可能性や、リグの構造を壊さずに配置をいつでも修正できる「後出しジャンケン」の強さにあります。
長年、Mayaで重いリグやコンストレイントの処理落ちと格闘してきましたが、Matrix機能と最新CPUの圧倒的な処理能力が合わさることで、1万個ものノードが破綻なく滑らかに動くのを目の当たりにした時、本当に感動しました。
それは単なるパフォーマンスの向上ではなく、Mayaのビューポートの向こう側に広がる、次元の違う表現の可能性に触れた瞬間でした。
Constraintに別れを告げ、Matrixの世界へ踏み出すことで、私たちのリギングやアニメーション表現はまだまだ限界を突破できるはずです。
🎁 【無料配布】あなたのPCで「1万個の限界テスト」に挑戦しませんか?
今回記事で使用した、AIと創り上げた変態的ベンチマークシーン(Level 1〜4)をセットにした一括ZIPファイルを、私のBOOTHショップにて無料配布いたします!
または、GUMROADよりダウンロードしてください。
Level 1の「Matrix vs Constraint」でご自身のPCのfpsを比較して絶望(?)するも良し、Level 4の「無限ギア」を超高速回転させて、Matrixの芸術的なうねりと圧倒的な処理能力を堪能するも良しです。すべて重いテクスチャ無しのピュアなノード計算なので、サクッとダウンロードして試せます。
それでは、第2回の検証編はここまでです。
次回以降は、ついに実戦で使えるMatrixリギングの具体的な手法を解説します。
お楽しみに!









コメント
コメント一覧 (2件)
次回がめちゃくちゃ気になります、是非読みたい!すぐ読みたい!
ありがとうございます。
ただいま執筆中ですので、しばらくお待ち下さい。